
Aptos Networks has achieved new performance and throughput milestones in its mainnet-like environment, Previewnet.


The Aptos Labs team has improved the scalability and performance of the network. These changes have been tested in the Previewnet environment. This article describes some of the impressive numbers and new industry milestones achieved in Previewnet, which ends at the end of November 2023.
In an environment that simulates the main network we did the
- Peak (TPS) of 30,000 peer-to-peer (p2p) transactions per second.
- Maintain a steady rate of 25,000 p2p transactions over several hours.
- Process 2 billion transactions in 24 hours.
- Over 1,000,000 limited series NFTs were cast in 90 seconds.
What is Previewnet?
To further optimize our system, the community and the Aptos Labs team are constantly working to improve the scalability, performance, and robustness of the Aptos network. All improvements will be fully tested on large-scale, multi-region clusters, but factors such as heterogeneous hardware, variable node configurations, non-uniform network characteristics, and the uniqueness of humans in node operations need to be taken into account in order to replicate the subtle characteristics of a globally decentralized platform.
Therefore, every major Aptos protocol change needs to be tested in depth in a test environment capable of simulating the future home network environment. This includes the deployment of nodes by the same node operators with all the characteristics of the corresponding main network nodes. This is necessary to fully validate each change to ensure that the new behavior is scalable, high performance, secure and reliable. We call this test environment "Previewnet".
As we continue to accumulate a large number of network changes, our node operators build a preview network where we test the network for extreme loads, heavy loads, and long periods of sustained activity. This blog summarizes the preview network we build in November 2023.
Setup and schedule
Below are key statistics and timelines for the recent Preview Network:
Number of validator nodes: 125 (5% higher than the main network)
Number of countries: 26 (same as main network)
Satoshi Nakamoto factor: 33 (compared to 17 for the main network)
Equity Distribution:
- EU: 40%
- Asia: 25%
- Americas: 26%
- Africa, Middle East and Australia: 9%
- Setup start date: October 30, 2023
- Test start date: November 6, 2023
- Test ends: November 21, 2023
- Total transactions processed: >9 billion (over two weeks)
The Preview Network setup reflects the characteristics of the main Aptos network in terms of geographic distribution, number of nodes, equity by geographic distribution, and number of unique node operators. Each operator has deployed servers that meet the Preview Network's specific single-node benchmarks. (If you want to run your own benchmarks, you can follow the steps here).
Due to the low distribution of equity per node, the Satoshi Nakamoto coefficient in the preview network is 33 compared to 17 in the main network, which means that the main network should have equal or better performance than this test result. As new validators are added to the main network, the network will be further decentralized. Our goal is to achieve a Satoshi Nakamoto factor of 30+ in the main network, which is why it is important to set up the preview network in a way that reflects the future distribution of equity in the main network.
Here are the details of the tests we conducted.
Performance and peak transactions per second (TPS)
(The Journey So Far: Earlier this year, we demonstrated the first fully repeatable performance benchmark to kick off an industry-wide discussion around the definition of performance metrics such as "transactions per second (TPS)". We demonstrated that our software stack can achieve approximately 20,000 TPS in a 100-node, globally geographically distributed network... As a quick recap, here are the key innovations that enabled Aptos to achieve the high throughput in the benchmark:
Horizontally Scalable Consensus with Quorum Store: Aptos achieves horizontal scalability using an innovative consensus mechanism based on the Quorum Store.The idea of the Quorum Store is to decouple data from metadata so that data dissemination can occur outside of the critical path of consensus.
Parallel Execution Engine with BlockSTM: To extend the execution layer, we designed BlockSTM, our parallel execution engine that executes transactions in parallel using Software Transaction Memory (STM) with optimistic concurrency control. Our benchmarks show that we can execute 160,000 transactions per second.
Highly optimized bulk storage: Aptos' storage approach combines persistence and in-memory lock free sparse Merkle trees that are specifically optimized for Block-STM for caching and parallelization.
Resource efficient phases using pipelining: pipelining the phases of transaction processing to fully utilize the resources so that throughput is limited only by the slowest phase (instead of combining all the phases into a sequence). Pipelining helps nodes to utilize all their resources at the same time, leading to a significant increase in throughput.
Achieving higher TPS spikes: using our repeatable benchmarks, we observed that the storage layer was becoming a bottleneck for us. We used an instance of RocksDB that could not write data to the database beyond about 20,000 transactions per second. To address this issue, we introduced a new sharded storage design that splits the state store into multiple RocksDB instances so that we can commit in parallel. In addition, we made several improvements to our execution engine, state synchronization algorithm, and network stack to increase throughput.
All of these improvements ultimately allowed us to reach a new peak of over 30,000 transactions per second in the Preview Network.
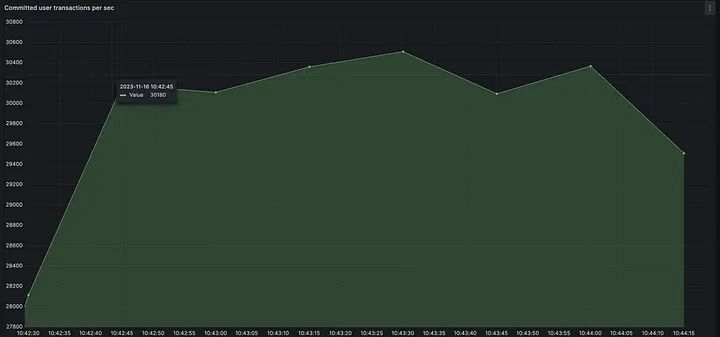
The Journey Ahead: Aptos aims to further improve scalability by setting 100,000 TPS per second as the next milestone, continuing to work toward a goal of over 1 million TPS per second. This ambitious goal is in line with Aptos' mission to build a network capable of serving billions of users and will lead the way for a new wave of adoption of Web3 technologies. Achieving higher TPS is critical to meeting the needs of the growing and diverse global user base in the Web3 ecosystem.
Sustained peak throughput - a new milestone for the industry!
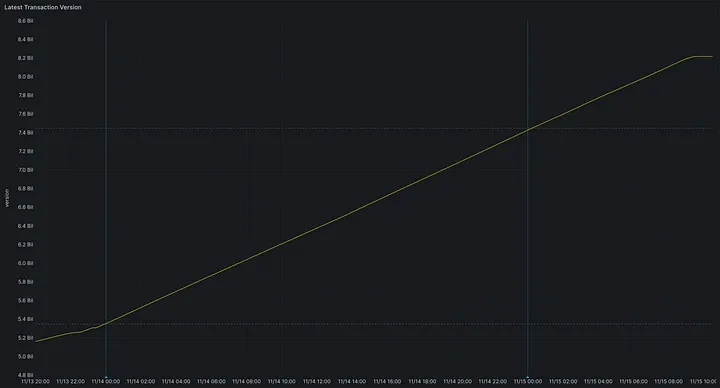
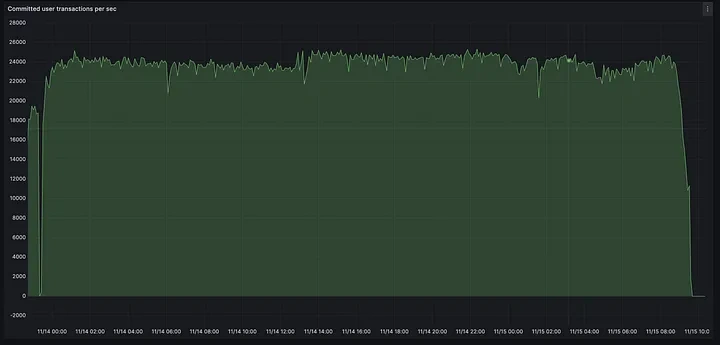
TPS spikes are only a small part of Aptos' overall throughput story. Networks built for billions of users must maintain high throughput for extended periods of time. With this in mind, we aggressively drove the network to perform sustained TPS of ~25k for 24+ hours. During this period, the network successfully processed an unprecedented 2.1 billion (with a B) peer-to-peer payment transactions without any downtime for 24 hours.Visanet processes 150 million transactions per day. The charts below show the sustained TPS and timestamps for this load in the Preview Network.
The Aptos network processed more than 2 billion transactions in one day - a new industry milestone!
Parallelizing Sequential Workloads
When discussing high throughput, much of the industry's attention has been focused on peer-to-peer transmission. This made sense in the past, as payments and transmission were the original use cases for cryptocurrencies. However, these use cases are no longer fully representative of the types of workloads we see in today's blockchain. Specifically, unlike transmission workloads, which can be easily parallelized, many existing workloads exhibit sequential properties. They require sequential execution and can significantly reduce throughput because they cannot simply be parallelized across execution cores.
An example is the minting of a limited supply of irreplaceable tokens (NFTs) with the sequential naming property. For example, it is only permissible to create an NFT collection of 1,000,000 NFTs, where each NFT is uniquely indexed in the order in which it was minted (i.e., each token is given a unique index based on the order in which it was minted, which is contained in the name of the token, e.g., "Superstar #143"). This is a common practice for NFTs.
Both limited availability and sequential naming require sequential execution, which can significantly reduce transaction throughput. To overcome this, we have developed a novel technique at Aptos called conflict-free counters, Aggregators.With Aggregators, we can remove sequential computation from the critical execution path and enable parallel execution while still maintaining the necessary sequential workload properties (i.e., despite parallel execution, the execution result is the same as for a sequentially executed workload). the same). We will cover the details of this technique in an upcoming blog post. For now, it is important to note that Aggregators allow us to parallelize otherwise sequential workloads.
Using Aggregators on previewnet, we were able to cast a full 1 million NFT collection in ~90 seconds and a 5 million NFT collection in ~8 minutes, with a sustained throughput of more than 10,000 NFTs per second.This is a 10x improvement over sequential execution (i.e., without Aggregators). The ability to seamlessly parallelize these workloads is currently unique in the industry.
Casting 1,000,000 Limited Collections in 90 Seconds NFT opens up new NFT use cases for supporting large-scale real-world events.
As we've shared before, over time, Aptos aims to work with our peers to develop the blockchain equivalent of the TPC benchmark as a fair and comprehensive way to compare performance between different networks. It should have a representative set of workloads that can be translated into real-world performance, providing valuable information to application builders and users. With this post, we introduce a new metric to this benchmark suite - "Sequential NFT casts per second" - with more to come.
We invite the industry to add "Sequential NFT casts per second" as an additional metric to the benchmark suite.
Disaster Recovery Drill (DR Drill)
While networks are designed from the start to be reliable, secure and fault-tolerant, there is always a need to plan for worst-case scenarios and build strong operational practices. We fortify every system component, but being prepared for all outcomes is critical. If an incident does occur, we need to be able to restore the network to full health as quickly as possible. To inject failures into the network, we ran an experimental feature. Together with our node operations community, we were able to identify and execute a script that was able to quickly bring the network back online.
Key lessons learned
The real world is more complex: previewnet reaffirms our contention that any protocol change must be certified in a real environment with a wide range of extreme and continuous workloads. While we have tested our changes on large, multi-region clusters, the Aptos mainnet is unique, with more features, variables, and heterogeneity than can be tested. As a result, we found subtle performance and reliability issues that we might otherwise have missed. These issues stem from the heterogeneity of operating systems, hardware, deployment architectures, storage technologies, network infrastructures, and carrier best practices. While test environments are necessary to validate changes, they are always inadequate compared to the real world.
Read paths are equally important: Most blockchain performance discussions center around write path latency and throughput. However, very little is said about read paths, such as read replication throughput and latency for full nodes, API services, and indexers. This is problematic because blockchain users now rely on these services to read and/or verify blockchain state. As a result, if the read path cannot maintain the same high (or higher) performance, the user experience will suffer, no matter how fast the write path processes transactions. We witnessed this briefly in previewnet, reminding us that read paths cannot be treated as second-class citizens.
High-quality tools are invaluable: previewnet explicitly reminds us that automated, high-quality tools are critical. When running large-scale experiments across heterogeneous deployments, the number of variables to consider can be overwhelming. This is especially true when debugging complex interactions and unexpected behavior. Tools are the only way to manage this complexity and effectively identify the problem at hand. For example, several nodes experienced CPU or disk bottlenecks during testing, and we relied on auto-generated flame graphs and metrics analysis to help identify the root cause. Similarly, during the previewnet configuration process, we utilized single-node benchmarking to help operators quickly validate the performance and correctness of their hardware choices, saving time before the network went live. Finally, the initial setup of the network took much longer than expected due to several inconsistent configurations, demonstrating the need for better tools in observation and deployment. Tools can save time at critical times.
A Tribute to Community
Previewnet has been an invaluable exercise for Aptos Network and its operators. We are very grateful to have an amazing community of node operators. They endured demanding schedules, upgrade requests and actively monitored the network. This camaraderie and enthusiasm drove us to bigger and better experiments throughout previewnet. Here are some comments from the node operator community.
"Aptos previewnet processes continue to help our team push the boundaries of our technology from both a hardware and software perspective. The process is rigorous but worth it every time we see the progress made.The Aptos team continues to lead in proficiency and expertise! " - Republic Crypto
"One of the most important things I learned during Previewnet 2 was that latency between the validator and the VFN is very important. Again, state synchronization performance is the glue that really holds the network together. It's very exciting to see significant performance gains from state synchronization improvements. 30k TPS is outrageous! " - Lavender Five
"The entire setup, configuration, migration and upgrade process was a great experience. Some upgrades went well. Some upgrades didn't work out, but we learned more from our failures, so there are always positives." - Artifact
"It was great to be able to test multiple uncommon scenarios in terms of synchronization that the test team had improved (for example). It was also great to be able to test the team's efforts in DAG consensus upgrades as well as pushing the network to its limits at the same time.The resilience of the Aptos network was demonstrated in this Previewnet, where several well known node operators worked together to optimize the hardware requirements, paving the way for a bright future for Aptos. " - Luganodes
All of the above content is reproduced from the Internet, does not represent the position of AptosNews, is not investment advice, investment risk, the market need to be cautious, such as infringement, please contact the administrator to delete.
 WeChat Sweep
WeChat Sweep  Alipay Sweep
Alipay Sweep 
